

IA – ARTIFICIAL INTELLIGENCE ‘ASSEMBLY’

| Exploração Profunda |
IA, Assembly e x64: Uma Exploração Profunda
IA e Assembly: Alguma Abordagens que podem ser Uteis para melhorar Performasse Matemáticas dos Grupos e entregar melhor desempenho no processo!
- A Inteligência Artificial (IA) e a linguagem Assembly, a mais próxima do hardware, podem parecer mundos à parte, mas sua combinação oferece um nível de controle e otimização sem precedentes.("Imagine" Um Kernel Voltado apenas para Controle de Conjuntos!)
- Por que unir IA e Assembly?
- Otimização extrema: O Assembly permite manipular diretamente os recursos do hardware, otimizando operações para tarefas específicas da IA, como cálculos de matrizes e convoluções.
- Hardware específico: Ao trabalhar diretamente com o hardware, é possível aproveitar ao máximo as características de aceleradores como GPUs e TPUs, essenciais para o treinamento de modelos de IA complexos.
- Compreensão profunda: Ao escrever em Assembly, você obtém uma compreensão mais profunda de como os algoritmos de IA são executados no hardware, permitindo identificar gargalos e otimizar o código de forma mais eficiente.
Exemplo: Desassemblando com o IDA Pro
O IDA Pro é um dos desassembladores mais populares, capaz de gerar código Assembly a partir de arquivos executáveis. Imagine que você tenha um modelo de rede neural convolucional treinado e queira analisar como ele está sendo executado no hardware. Ao abrir o 'Debug Kernel' no IDA Pro, você pode ver o código Assembly gerado pelo compilador, identificando as instruções específicas utilizadas para realizar as operações de convolução, pooling e ativação.
Modelos de IA e Representação em Memória
Um modelo de IA, como uma rede neural, pode ser representado em memória de várias formas:
- Pesos sinápticos: Armazenados em arrays multidimensionais, os pesos sinápticos definem as conexões entre os neurônios da rede.
- Ativações: Os valores de ativação dos neurônios em cada camada são armazenados em arrays.
- Bias: Valores constantes adicionados às ativações dos neurônios.
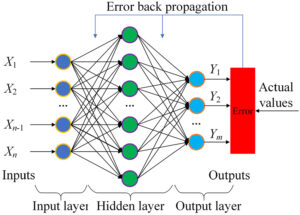
Alocação de Memória em x64:
Em arquiteturas x64, a memória é alocada em páginas de 4KB. O sistema operacional gerencia a alocação e liberação dessas páginas. Para modelos de IA, é comum utilizar alocadores de memória personalizados para otimizar o desempenho, como o TensorFlow Allocator.
Organização dos Processamentos:
Os processamentos em modelos de IA envolvem:
- Cálculo de produtos escalares: Realizados entre vetores de pesos e vetores de entrada.
- Funções de ativação: Aplicadas aos resultados dos produtos escalares para introduzir não-linearidade.
- Backpropagation: Algoritmo utilizado para ajustar os pesos da rede durante o treinamento.
Essas operações são geralmente implementadas em loops, aproveitando as instruções SIMD (Single Instruction, Multiple Data) das CPUs modernas para processar múltiplos dados em paralelo.
Kernel Linux para IA: Uma Abordagem Dedicada
Um kernel Linux customizado para IA poderia oferecer diversas vantagens:
- Alocação de memória otimizada: O kernel poderia implementar um alocador de memória customizado para as necessidades específicas dos modelos de IA, reduzindo a fragmentação da memória e melhorando o desempenho.
- Escalonamento de tarefas otimizado: O escalonador poderia priorizar as tarefas relacionadas à IA, garantindo que os recursos do sistema sejam alocados de forma eficiente para o treinamento e inferência de modelos.
- Suporte a hardware acelerado: O kernel poderia fornecer drivers otimizados para GPUs e TPUs, permitindo que os modelos de IA sejam executados de forma mais rápida e eficiente.
- Isolamento de processos: O kernel poderia isolar os processos relacionados à IA, garantindo que eles não sejam afetados por outros processos em execução no sistema.
Recursos adicionais:
- Livro: "The Art of Assembly Language" de Randy Hyde